|
|
These are the remainings of the _old_ roboshock pages.
The new pages can be found here
|
Die RS-Architektur, eine selbstlernende Software
Ich möchte hier eine von mir überlegte SW-Architektur vorstellen, die ich mangels
besserer Ideen die Roboshock-Architektur (RS-Architektur) nenne.
Die Grundidee dieser Architektur besteht darin, dass der Roboter (bzw. die KI) durch Beobachtung seiner Situation
und der Umwelt über sich und die Welt etwas lernt.
Mit Hilfe all dieses Gelernten soll der Roboter dann Wege finden, ein vorgegebenes Ziel zu erreichen.
Allerdings gibt es dabei ein gewisses Start-Problem: Solange die AI noch sehr wenig weiss,
weiss sie auch nicht, was sie am besten tuen soll, um die richtigen, für sie wichtigen
Dinge zu lernen. In einfachen Welten kann man eine AI auch einfach herumprobieren lassen,
damit sie Ihre Welt kennenlernen kann. Die hier zugrundeliegende Welt (also die hier zu berücksichtigen
Aspekte der realen Welt) ist für einen solchen Ansatz aber viel zu komplex. Menschen wie Tiere
schauen sich deshalb von anderen ab, was sie tuen könnten. (Wären Sie jemals auf die Idee gekommen,
Aktien zu kaufen, wenn es nicht andere in Ihrem Umfeld getan hätten?)
Zwar fehlt dem Roboter vorerst jegliche Möglichkeit, um visuell von anderen abzugucken - sein Input
über Körperbewegungen beschränkt sich auf sein Wissen über seine eigenen aktuellen Servopositionen.
Aber das reicht doch:
Beibringen statt herumprobieren lassen
Als "Teaching" können dem Roboter beispielhafte Bewegungsfolgen
gegeben werden, welche er dann "ausarbeitet", also immer wieder versucht,
sie trotz seiner nicht vollkommen deterministischen Mechanik und trotz etwaiger Störungen von aussen
zu reproduzieren. Sobald ihm dies gut gelingt, wird Langeweile aufkommen, und er wird
die Bewegungen immer mehr variieren, und dabei noch mehr über das Situationsumfeld und die Grenzen dieser
Bewegungen lernen.
Aktives Beibringen ist nur eine Variante des "abgucken lassens"!
|
Goal-System und Sensomotorisches Subsystem
Die RS-Architektur ist in zwei Ebenen unterteilt:
- High-Level AI: Goal-System
- Low-Level AI: SeMoSystem (Sensomotorisches Subsystem)
Die High-Level AI wird mit vielen, vielen sich konkurierenden Goals hantieren müssen, wird also
insbesondere eine Art Projektmanagement-Modul beinhalten müssen.
Das sensomotorische Subsystem hingegen bearbeitet immer nur ein Ziel zu einer Zeit.
Die Schnittstelle zwischen den beiden Systemen sieht sehr einfach aus:
Das Goalsystem wählt ein in diesem Moment zu erreichendes Ziel aus,
und gibt dieses als Goal-State nach unten weiter. Dort versucht das SeMoSystem,
von der aktuellen Situation (current state, Scur) ausgehend einen Weg zu finden,
den Goal-State zu erreichen.
Sensomotorisches Subsystem
Zur Zeit arbeite ich nur an der Realisierung des SeMoSystems.
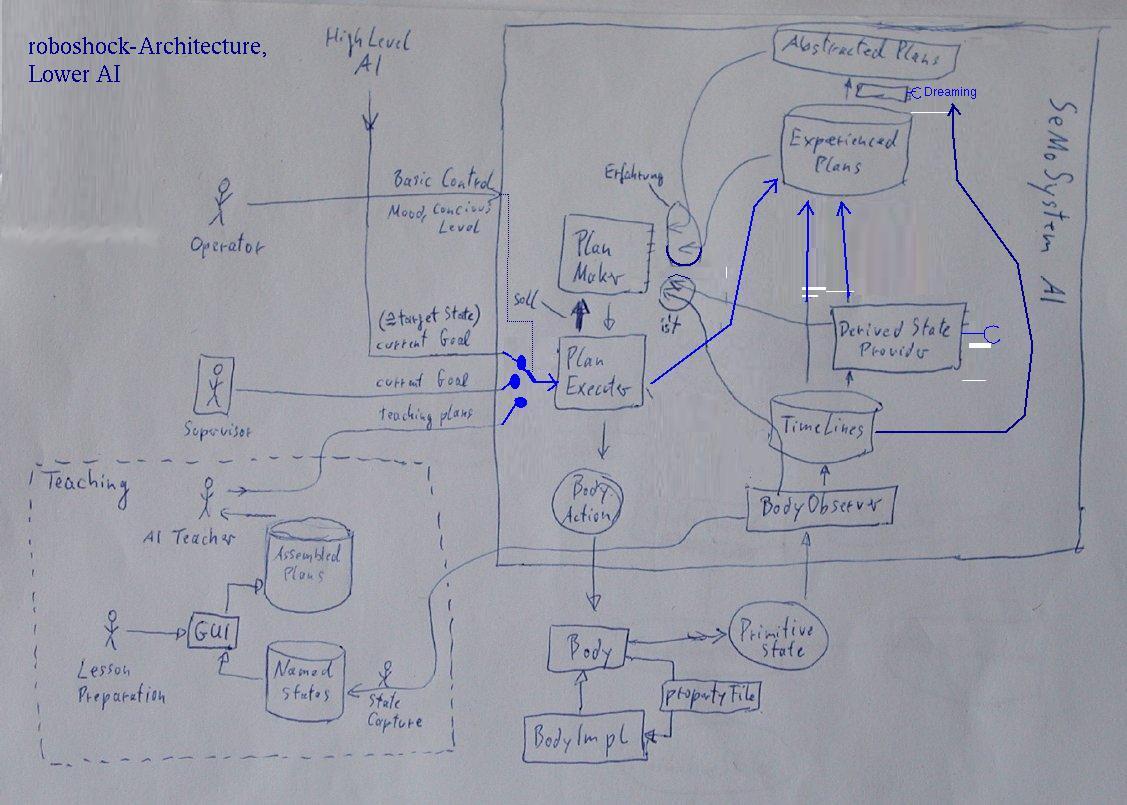
Hier ein Schaubild zur Architektur:
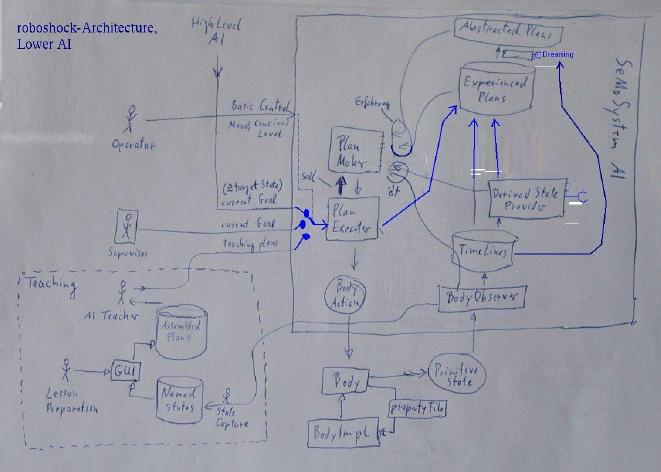
Größer
Lernen kann der Roboter zum einen durch die Beobachtung seiner Selbst und der Umwelt,
während er mehr oder weniger zufällige Aktionen ausführt, oder indem er etwas beigebracht bekommt.
Dieses Beibringen ist - wie oben schon erwähnt - im einfachsten Fall das
"Vormachen eines Bewegungsablaufes" in Form eines TeachingPlan, was letztlich wieder auf die Beobachtung seiner Selbst
und der Umwelt zurückführt, nur dass er dabei nicht beobachtet, wie er selbst seinen Körper
steuert, sondern wie jemand anderes (konkret der TeachingPlan) seinen Körper steuert. Für die
weitere Verarbeitung der dabei entstehenden Beobachtungen ist es aber egal, wie sie zustande kamen.
Der Roboter lernt also, indem er sich und die Welt über die Zeit beobachtet. Durch das Ausführen von Aktionen kann er
seine Beobachtungen bereichern.
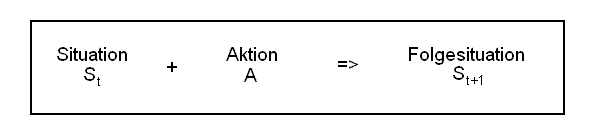 Ein zentrales Element der RS-Architektur ist somit die Wissens-DB. Dort werden alle
Beobachtungen abgespeichert.
Ein zentrales Element der RS-Architektur ist somit die Wissens-DB. Dort werden alle
Beobachtungen abgespeichert.
 In dem Moment, in dem die SW losläuft, beginnt also der Roboter zu lernen:
Er beobachtet seine Sensoren und Servostellungen, und lernt - entsprechende Servo-Startwerte
vorausgesetzt - als
erstes "Wenn ich so stehe, dann bleibe ich so stehen. Die Lot-Sensoren melden
keine Veränderung". Ein großer Lernerfolg, der natürlich gleich in die Wissens-DB
eingetragen wird!
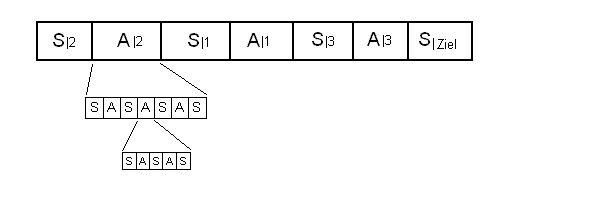
Anmerkung: Später werde ich die Situation-Aktion-Situation Elemente um eine Zeitangabe erweitern. Es ist
die Zeit, die nach der Aktion typischerweise vergeht, bis die Folgesituation eintritt.
Die SAS-Tabelle wird dann zur SATS-Datenbank.
In dem Moment, in dem die SW losläuft, beginnt also der Roboter zu lernen:
Er beobachtet seine Sensoren und Servostellungen, und lernt - entsprechende Servo-Startwerte
vorausgesetzt - als
erstes "Wenn ich so stehe, dann bleibe ich so stehen. Die Lot-Sensoren melden
keine Veränderung". Ein großer Lernerfolg, der natürlich gleich in die Wissens-DB
eingetragen wird!
Anmerkung: Später werde ich die Situation-Aktion-Situation Elemente um eine Zeitangabe erweitern. Es ist
die Zeit, die nach der Aktion typischerweise vergeht, bis die Folgesituation eintritt.
Die SAS-Tabelle wird dann zur SATS-Datenbank.
Pläne
Wenn eine grundlegende Menge an Wissen gesammelt ist, könnte die Zielvorgabe,
eine bestimmte Situation (=Sziel) zu erreichen, folgendermassen erreicht werden:
Wenn zum Beispiel die Zielvorgabe der Folgesituation S(t+1) des Eintrages 3 entspricht,
und die aktuelle Situation der Ausgangssituation des Eintrages 2, dann können weitere
Einträge gesucht werden, um eine Überführung von S(t+1) der Zeile 2 zu S(t) der Zeile 3 zu finden.
Wenn z.B. S(t+1)|2 == S(t)|1 und S(t+1)|1 == S(t)|3,
dann kann folgender Plan zur Erreichung des Zieles geschmiedet werden:
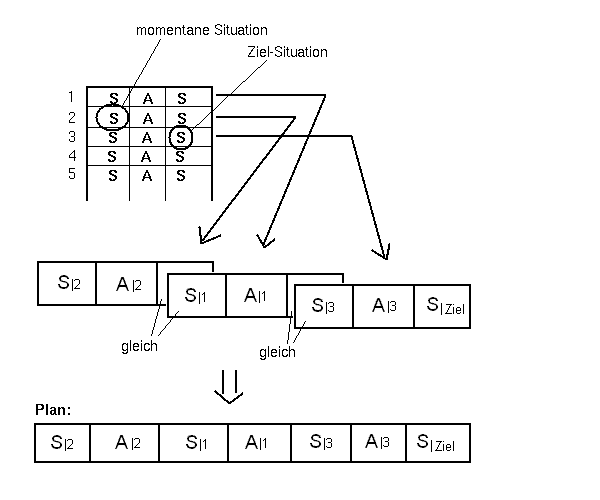 Die RS-Architektur beinhaltet also einige sehr interessante Merkmale:
Dem Roboter ist es möglich, Wissen zu sammeln. Dem Roboter ist es möglich, mit Hilfe
seines gesammelten Wissens Pläne zu machen! Und wer weiss: Für komplexere
Aufgaben kann es nötig sein, zu einer ruhigeren Stunde länger nach Lösungswegen
zu suchen. Sind wir hier sogar schon beim träumen?
Ein weiterer Moment solcher Pläne ist, dass sie eine "Kommunikations-Schnittstelle
zum Entwickler" bieten: Dieser kann dem Roboter nun etwas "beibringen", indem
er dem Roboter einen Plan vorstellt, also eine Abfolge von Situationen und Aktionen.
Durch Vergleich der Situationen des Planes mit den Sonsordaten kann der Roboter
feststellen, ob er noch "auf dem richtigen Weg" ist. Dadurch wird der Plan weit mehr,
als eine starre, pseudo-programmierte Bewegungsfolge. Zum Beispiel kann sich der
Roboter entscheiden, den Plan zu verlassen, oder einen anderen Plan einzuschieben
(etwa einen Plan zum Abfangen eines nicht gewollten Umkippens).
Die RS-Architektur beinhaltet also einige sehr interessante Merkmale:
Dem Roboter ist es möglich, Wissen zu sammeln. Dem Roboter ist es möglich, mit Hilfe
seines gesammelten Wissens Pläne zu machen! Und wer weiss: Für komplexere
Aufgaben kann es nötig sein, zu einer ruhigeren Stunde länger nach Lösungswegen
zu suchen. Sind wir hier sogar schon beim träumen?
Ein weiterer Moment solcher Pläne ist, dass sie eine "Kommunikations-Schnittstelle
zum Entwickler" bieten: Dieser kann dem Roboter nun etwas "beibringen", indem
er dem Roboter einen Plan vorstellt, also eine Abfolge von Situationen und Aktionen.
Durch Vergleich der Situationen des Planes mit den Sonsordaten kann der Roboter
feststellen, ob er noch "auf dem richtigen Weg" ist. Dadurch wird der Plan weit mehr,
als eine starre, pseudo-programmierte Bewegungsfolge. Zum Beispiel kann sich der
Roboter entscheiden, den Plan zu verlassen, oder einen anderen Plan einzuschieben
(etwa einen Plan zum Abfangen eines nicht gewollten Umkippens).
Phantasie
Der hier vorgestellte Ansatz, alle Erfahrungen in die Wissens-DB aufzunehmen,
unterscheidet sich übrigens schon von vielen anderen selbstlernenden Architekturen:
Oft werden Erfahrungen sofort als "gut" oder "schlecht" eingeordnet, und das
Wissen über vermeintlich "schlechtes" mitunter sogar komplett verworfen.
Mit einem solchen Ansatz verschenkt man sich viel Potential, denn alles,
was zum Erreichen des eines Zieles schlecht ist, kann zur Erreichung
eines anderen Zieles durchaus gut sein. Auch das aktuelle Ziel ist vielleicht
nur über Umwege erreichbar. Wenn eine Zwischensituation hier zu schnell als
"schlecht" eingestuft und alle damit verbundenen Zusatzinformation verworfen
werden, kann vielleicht nie der Weg zum Ziel gefunden werden.
In diesem Hinblick kann dann vielleicht Phantasie verstanden werden als die
Bereitschaft, einen Teilplan nicht von den weiteren Überlegungen auszuschliessen,
nur weil er zunächst vom Ziel weg führt.
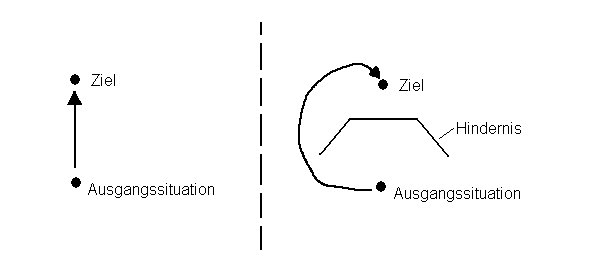 Mehr Phantasie erzeugt also mehr genauer zu durchdenkende Pläne, benötigt also auch
mehr Rechenzeit. Also können zu nicht aktiven Zeiten ("Schlafzeiten") auch
phantasievollere Überlegungen angestellt werden.
Auch passt diese Überlegung mit der
verbreiteten Meinung zusammen, dass Phantasie ein Gradmesser der Intelligenz sei.
Mehr Phantasie erzeugt also mehr genauer zu durchdenkende Pläne, benötigt also auch
mehr Rechenzeit. Also können zu nicht aktiven Zeiten ("Schlafzeiten") auch
phantasievollere Überlegungen angestellt werden.
Auch passt diese Überlegung mit der
verbreiteten Meinung zusammen, dass Phantasie ein Gradmesser der Intelligenz sei.
Aktionen etwas konkreter
Ein einfaches System mit wenig Unterscheidungen spricht oft für einen guten,
allgemeingültigen Ansatz. Wenn man sich zu den Aktionen nähere Gedanken macht,
bemerkt man aber schnell, dass folgende Unterscheidung nötig ist: Es gibt
elementare Aktionen, nämlich das Bewegen der Aktoren (z.B. der Servos).
Alle anderen Aktionen müssen letztlich auf diese elementaren Aktionen
zurückführbar sein - denn sonst haben wir nichts zum agieren.
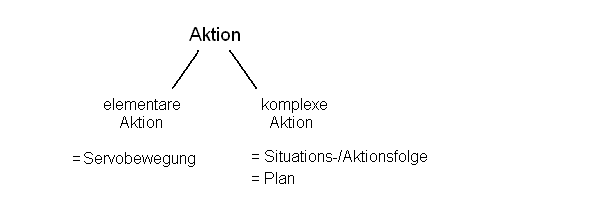 Eine Aktion ist also entweder eine Servobewegung, oder ein ganzer Plan.
Die Umsetzung eines solchen Planes wird zu weiteren untergeordneten Plänen führen,
und diese irgend wann zu einzelnen Servobewegungen.
Eine Aktion ist also entweder eine Servobewegung, oder ein ganzer Plan.
Die Umsetzung eines solchen Planes wird zu weiteren untergeordneten Plänen führen,
und diese irgend wann zu einzelnen Servobewegungen.
Situation (State)
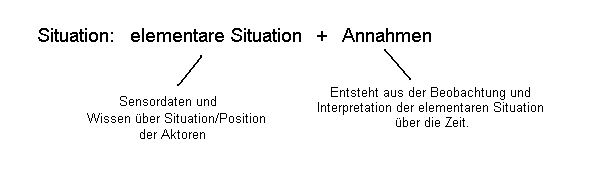
Auch der Begriff der Situation bedarf einer genaueren Betrachtung. Es gibt
"hard facts", das sind die Daten der Sensoren. Alles andere sind nur Vermutungen,
die sich letztlich aus der Beobachtung der Sensoren über die Zeit und in Hinblick
auf einen gegebenen Situationskontext ergeben. Allerdings ist der "gegebene
Situationskontext" auch wieder nur eine Vermutung! (Ein gefundenes Fressen
für Philosophen :-)
 Der eigentliche Sinn und Zweck einer Situation besteht darin, sie wiederzuerkennen, wenn sie
wieder eintritt.
Ein zentrales Problem besteht darin, dass die Menge der abgeleiteten Situationselemente
prinzipiell unendlich sein kann. Es ist eine der entscheidenden Aufgaben der RS-Architektur,
hilfreiche Situationselemente zu definieren, sowie vorher definierte, aber wenig
hilfreiche, auch wieder aus dem System zu entfernen. Hilfreich sind genau diejenigen, die
einen entscheidungsrelevanten Aspekt der Gesamtsituation möglichst zuverlässig darstellen.
Entscheidungsrelevant bedeutet, dass aufgrund dieses Situationselementes zu gegebener Zeit
für oder gegen einen bestimmten Subplan entschieden werden wird.
Der eigentliche Sinn und Zweck einer Situation besteht darin, sie wiederzuerkennen, wenn sie
wieder eintritt.
Ein zentrales Problem besteht darin, dass die Menge der abgeleiteten Situationselemente
prinzipiell unendlich sein kann. Es ist eine der entscheidenden Aufgaben der RS-Architektur,
hilfreiche Situationselemente zu definieren, sowie vorher definierte, aber wenig
hilfreiche, auch wieder aus dem System zu entfernen. Hilfreich sind genau diejenigen, die
einen entscheidungsrelevanten Aspekt der Gesamtsituation möglichst zuverlässig darstellen.
Entscheidungsrelevant bedeutet, dass aufgrund dieses Situationselementes zu gegebener Zeit
für oder gegen einen bestimmten Subplan entschieden werden wird.
Kodierung von Situationselementen - SINs
In der RS-Architektur werden abgeleitete States - also alles ausser primitive States, d.h. Sensorwerte -
durch plugable SW-Module, ich nenne sie StateIndicatoren, kurs SINs, zur Verfügung gestellt.
(Assoziationen zum deutschen "Sinn" sowie zum englischen "sin" sind natürlich rein zufällig ;-).
Jeder SIN signalisiert genau einen State, und kann dafür auf alle primitive States sowie
auf andere SINs zurückgreifen.
Wie diese SINs implementiert sind, ist dabei
völlig egal. Der eine kann ein NN sein, der nächste eine mathematische Formel, und der
nächste ein EM-Algorithmus. Allerdings wäre eine durchgängige Implementierung als NNs
recht attraktiv, denn dann könnte das gesamte SIN-Netz als ein großes
neuronales Netz aufgebaut sein, und auf möglicherweise bald kommende hochperformante
NN-Implementierungen a la CUDA oder opencl aufbauen (aber das sind nur wilde
Zufunktsideen).
Dynamischer Situationsraum
Ganz wichtig bei Plänen ist,
dass ein untergeordneter Plan nicht jedesmal der gleiche sein wird, obwohl doch die Eingangssituation
(= Ausgangssituation des vorigen Schrittes) immer die gleiche ist. Das liegt
daran, dass die Eingangssituation nicht wirklich GLEICH der Ausgangssituation des vorigen Schrittes
ist. Vielmehr handelt es sich hierbei um eine "is-a"-Beziehung. Die Ausgangssituation des vor-Schrittes ist
ein Goal-State, eine endliche Liste von Situationselementen, die zutreffen sollen, eine Wolke in einem
Situationsraum endlicher Dimensionen. Die Eingangssituation
für den nächsten Schritt hingegen ist die real existierende Situation, in der sich der Roboter befindet.
(Well, nicht die reale Situation, sondern das, was der Roboter glaubt, was die reale Situation sei.)
Es ist ein Punkt in einem tausend-dimensionalen Situationsraum. Dieser Situationsraum beinhaltet
vielleicht Situationselemente, die es beim vorigen mal noch gar nicht gab. Deshalb kann in einer
vermeintlich gleichen Situation wie früher, plötzlich zur Erreichung
des nächsten Goal-States ein anderer, vermeintlich besserer Subplan ausgewählt werden.
|
|
|